Since this post, the underlying model has been upgraded multiple times, and JSSG is now the primary transformation engine. AI-assisted codemod creation is also available locally via Codemod MCP.
In a previous technical post, we introduced an iterative approach to improve the accuracy of autogenerated codemods by integrating deterministic software engineering tools with AI. This approach significantly improved accuracy when using a single pair of before and after code examples to generate a codemod.
However, during a real-world scenario, the user provides more than one example pair in order to cover various edge cases. So, to further improve the practicality and effectiveness of our approach, we added the ability to generate a codemod given multiple pairs of before and after code examples. We then evaluated this new feature on our public registry.
We evaluated our iterative refinement process on a dataset of 57 real-world codemods sourced from our public registry. Each sample in the dataset included between 1 and 28 pairs of before and after code examples. We used Codemod AI and GPT-4o to generate codemods. Our primary evaluation metric was accuracy which was measured as the percentage of codemods that were correctly generated by the model across the dataset. The correctness of a codemod in the multiple-example scenario means that a codemod is only correct if it is free of compiler errors and can transform all the provided before examples to the expected after examples.
When Codemod AI is used without any refinement iterations and multiple code examples, the accuracy is 38.6%, or 22 out of 57 correct codemods. Note that Codemod AI without any refinement iterations is similar to using vanilla GPT-4o with our highly optimized prompt. By increasing the number of refinement iterations to three, we reach a 64.91% accuracy, or 37 out of 57 correct codemods.
The chart below illustrates the effect of increasing refinement iterations:
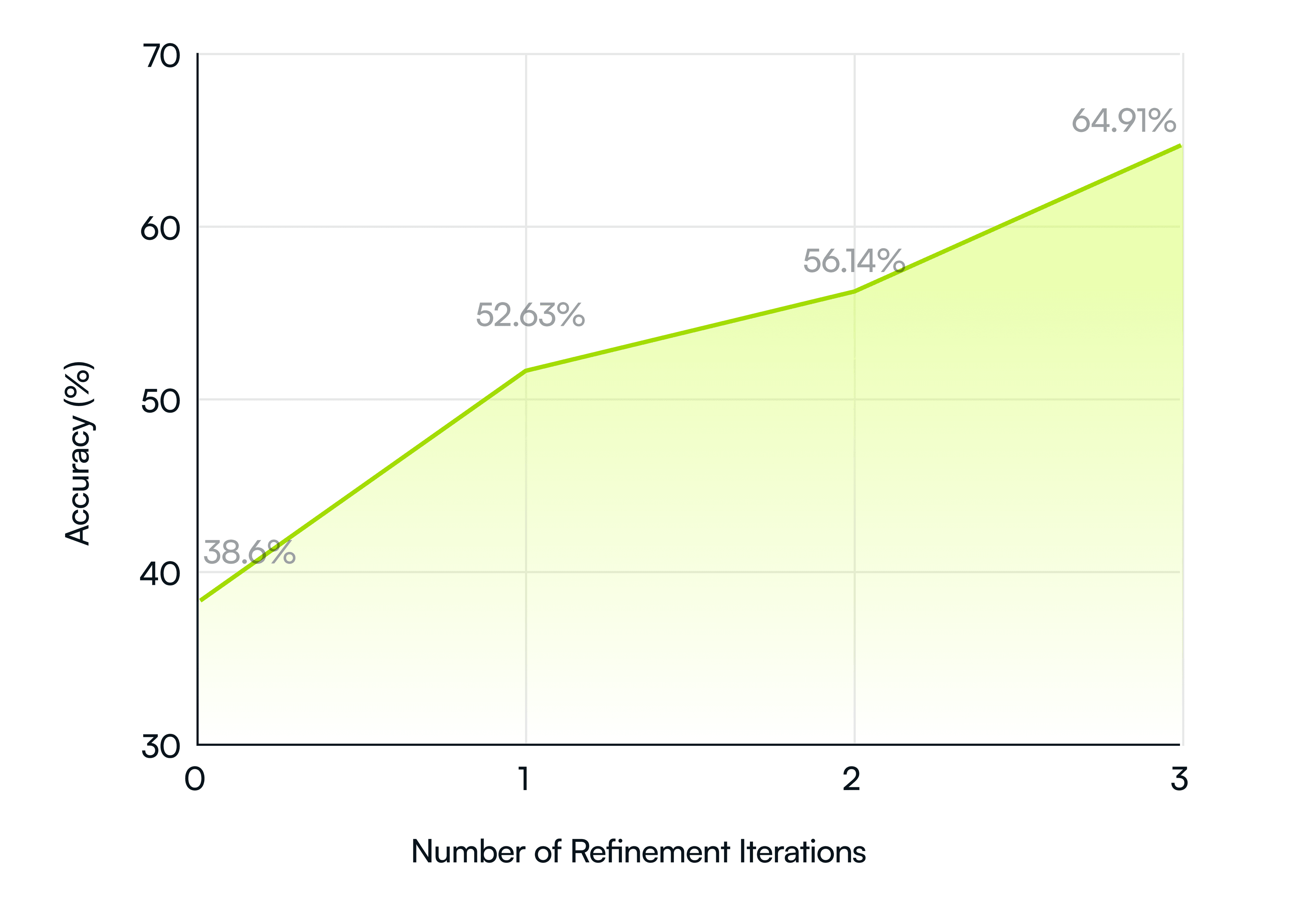
Satisfying more constraints means potentially more sophisticated codemods, i.e., codemods that are more difficult to generate via AI. Quantifying this difficulty is the purpose of our following analysis. The analysis shows that Codemod AI with three refinement iterations is able to generate codemods that pass at least half the test cases in 78.95% of the cases, or 45 out of 57 codemods. However, codemod generation becomes more difficult as the number of before and after pairs increase. This is shown in the drop we observe in the accuracy. The following chart summarizes these results.
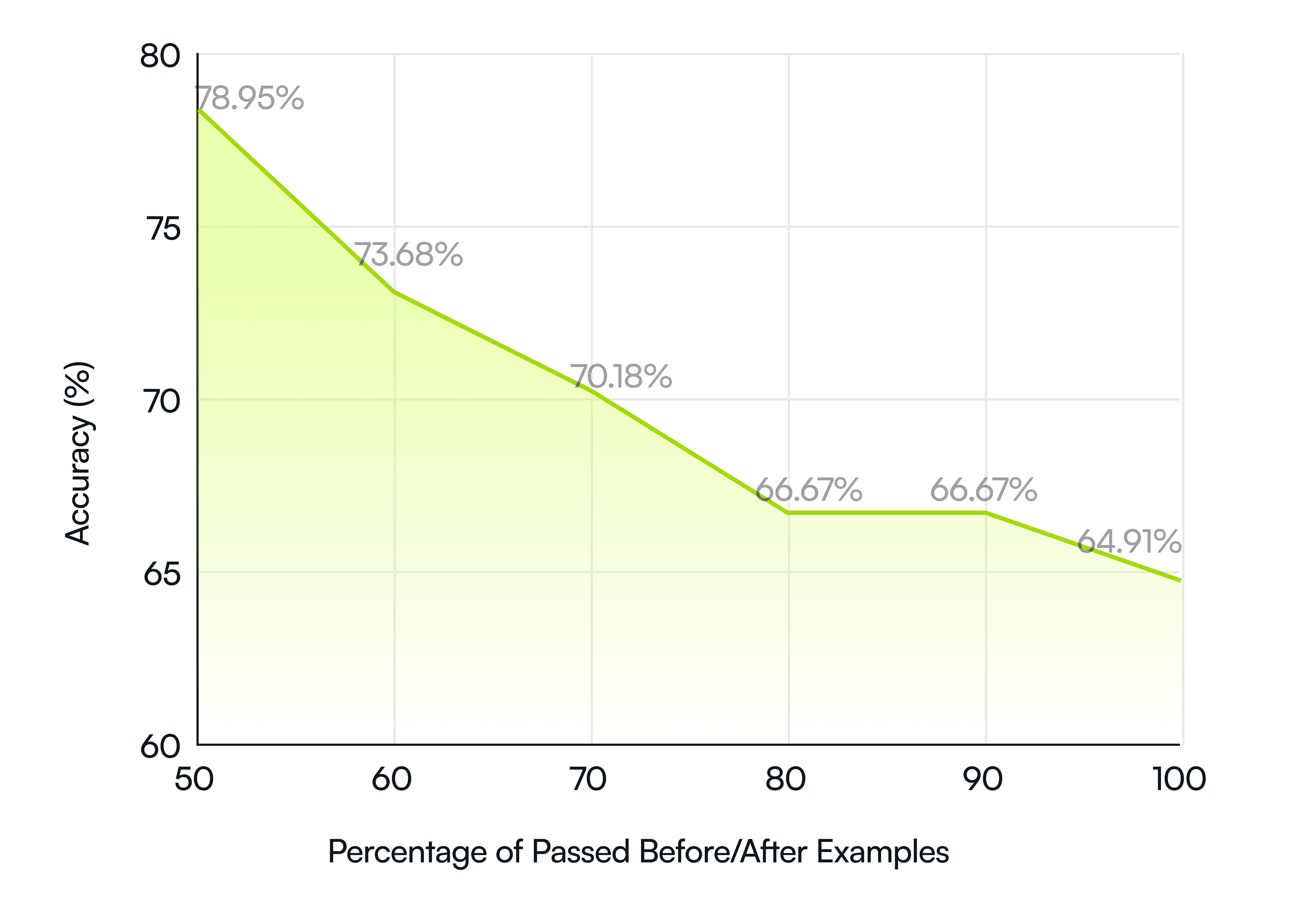
The results demonstrate that our iterative approach continues to be effective when dealing with multiple before and after examples. Even when the model cannot perfectly generalize to all examples, it can capture at least some of the desired transformations.
This evaluation is our most realistic yet, as it guides the model to create a codemod that passes all given test cases. Future work will focus on improving generalization and exploring techniques to leverage multiple examples more effectively within the iterative refinement process.