If I walked into a company with a tangled C# or .NET service architecture, I wouldn’t assume the first problem is the code itself.
I’d look at the boundaries.
In most legacy systems, risk doesn’t come from the age of the language. It comes from years of small decisions that gradually mixed communication, serialization, business logic, security, retries, and infrastructure concerns into the same execution paths.
Over time, service calls start carrying hidden assumptions:
- payload formats
- timeout behavior
- auth expectations
- serialization defaults
- side effects
- retry semantics
That’s when changes become expensive. Not because engineers can’t modify the code, but because nobody can confidently predict the blast radius.
That’s the real modernization problem.
The patterns are surprisingly consistent across large legacy .NET systems.
A service directly calls another service:
Loading code sample...
And the receiving service:
Loading code sample...
Individually, none of this looks terrible.
That’s exactly why these patterns spread.
But at scale, you eventually get:
- tightly coupled services
- weakly enforced or inconsistent contracts
- multiple serialization behaviors
- duplicated infrastructure logic
- inconsistent security enforcement
- transport concerns mixed with business rules
- little visibility into dependencies between services
The result is a system where even small changes feel risky.
Based on my experience working with many teams, what usually happens is that a platform team publishes migration guidance, and then individual teams handle the migration themselves using their preferred coding agents, workflows, and local conventions.
For one isolated migration path, this approach can work.
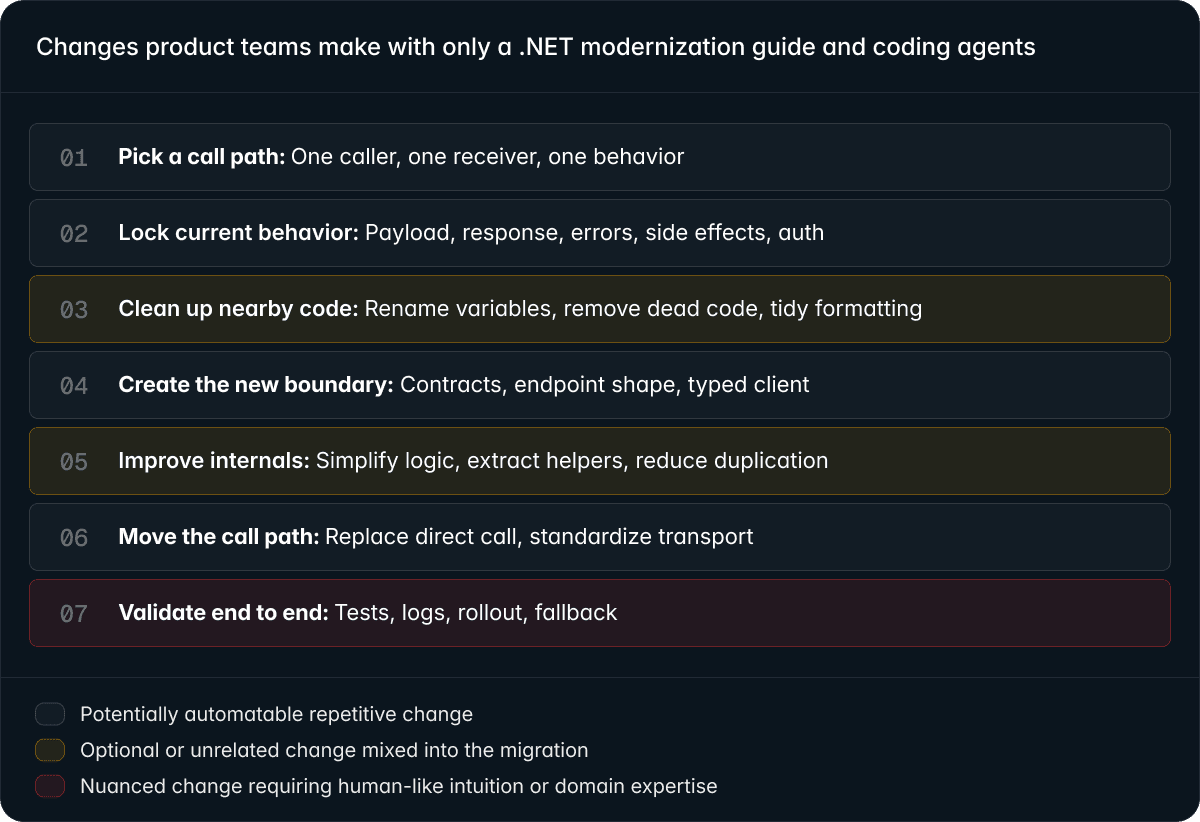
An engineer or coding agent manually works through the migration step by step. But the scope naturally expands beyond the required changes. While touching the code, teams often rename variables, clean up formatting, extract helpers, remove dead code, or apply optional refactors.
Now safe mechanical changes become mixed with risky manual edits and unrelated cleanup in the same PR.
The result is a bloated migration PR that becomes harder to review, validate, and roll out safely, while relying heavily on individual developer judgment.

The bigger problem is that almost none of this workflow becomes reusable. Team A manually goes through discovery, validation, cleanup, and rollout, while Team B repeats many of the same steps again in a slightly different way.
At enterprise scale, this breaks down quickly.
Large systems contain thousands of similar migration paths spread across many services and repositories, often built by different teams over many years. Documentation becomes outdated, services evolve independently, and the same pattern exists in many slightly different forms.
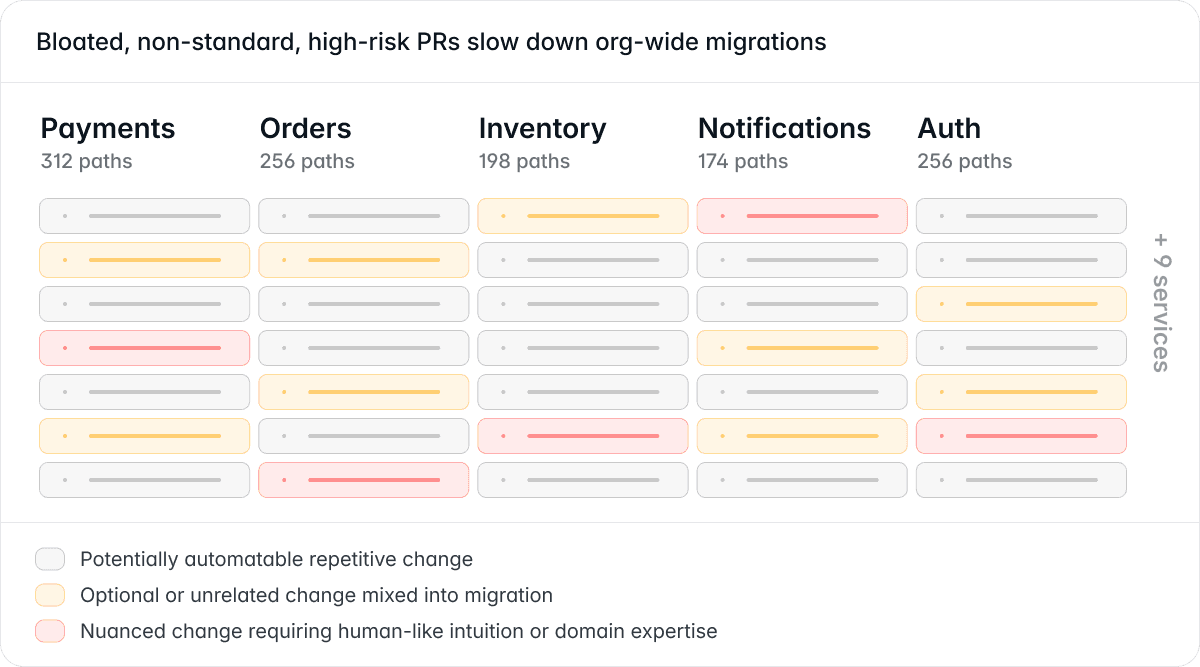
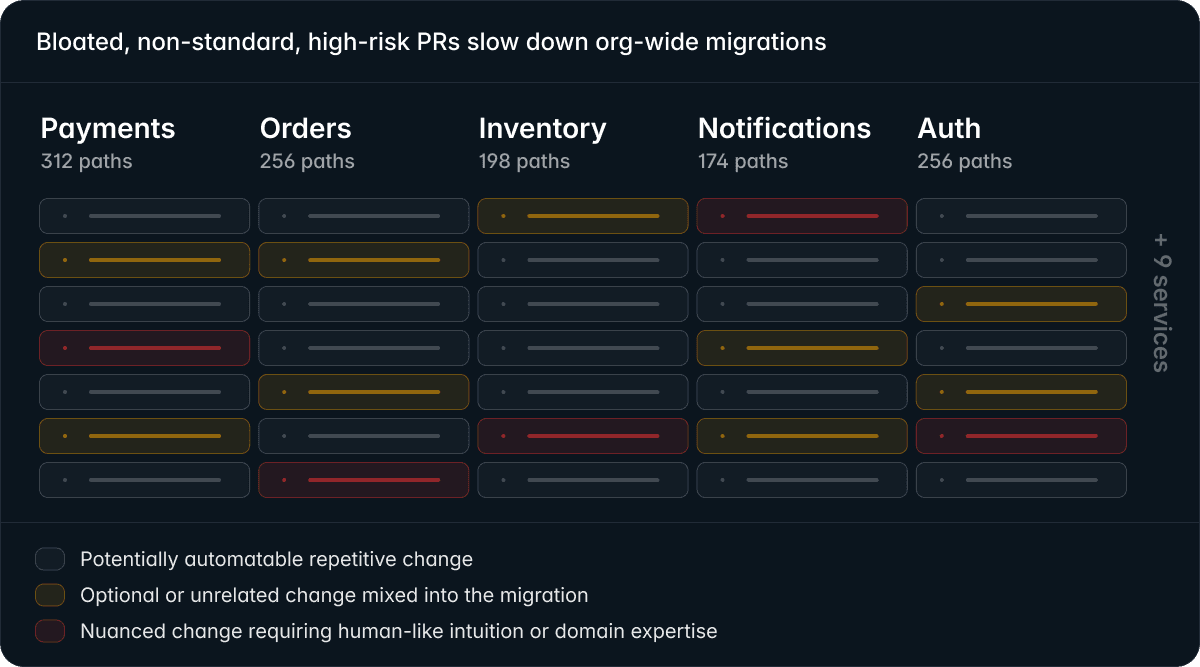
Without shared tooling, standardized workflows, and clear migration boundaries, every team starts reinventing the migration differently. Some rewrite aggressively. Others patch around the problem. Others delay the migration entirely.
The result is predictable:
- bloated and risky PRs
- duplicated migration work
- inconsistent implementations
- review bottlenecks
- stalled rollouts
- increasing architectural drift
At that point, modernization stops being just a coding problem. It becomes a human and organizational problem.
At enterprise scale, migrations stop being purely technical projects. They become organizational challenges around confidence, trust, and coordination.


Fleet-wide migrations are large organizational bets. Before platform teams can rally leadership and impacted teams, they first need confidence themselves.
They need to know:
- which maintenance projects are actually worth funding
- the expected effort, risk, ROI, and engineering impact
- the real blast radius across services and teams
- whether the migration can improve velocity without destabilizing production
Without that visibility, migrations often stall before they even begin.
To drive adoption, platform teams need to earn engineers’ trust. Trust in the tools, the migration process, and the people driving the initiative.
Impacted teams naturally hesitate when another team mandates a migration:
- Will this break production?
- Will this turn into weeks of manual cleanup?
- Will this disrupt my roadmap?
That hesitation is usually rational. Trust is earned through predictable and safe execution, not top-down mandates alone.
Large migration PRs often mix simple mechanical changes with risky manual edits, making them difficult to review, validate, and deploy safely. The more migration work feels unpredictable, the more teams resist adoption.
Large migrations fail less because of technology and more because of coordination overhead across dozens of teams.
Engineers dislike the non-technical work that pulls them out of flow:
- rollout coordination
- dependency tracking
- ownership discovery
- status reporting
- migration sequencing
- cross-team communication
The heavier and riskier the process feels, the more teams avoid it.
At scale, coordination overhead often becomes harder than the code transformation itself.
Eventually these systems start affecting:
- incident frequency
- operational stability
- developer velocity
- maintenance costs
- product delivery speed
In the AI era, this matters even more.
Companies that cannot evolve their systems safely and continuously eventually lose execution speed.
If I had to modernize a large legacy .NET system, I’d start small.
I’d begin with a few representative files and manually work through the migration with a coding agent to understand the exact workflow required to safely roll it out in production.
At this stage, the goal is discipline:
- make dependencies visible
- introduce enforceable boundaries
- reduce coupling gradually
- standardize infrastructure behavior
No optional refactors. No unrelated cleanup. No architectural redesign mixed into the same PR.
Once the workflow becomes clear, I’d break the migration into small atomic steps:
- repetitive and mechanically verifiable changes
- changes requiring human judgment or domain expertise
From there, I’d automate as many repeatable transformations as possible using compiler-aware codemods and deterministic tooling.
For the remaining edge cases, I’d isolate them into smaller reviewable tasks with the right context and guidance for AI systems or engineers to handle separately.
The goal is to turn a risky and inconsistent migration into a repeatable workflow that scales safely across teams and repositories.


Before changing anything, I’d want a code-level dependency map.
Not architecture diagrams.
Reality.
Patterns like:
Loading code sample...
Something like:
Loading code sample...
This changes the conversation from guessing to knowing.
This is where compiler-aware automation becomes useful.
Not as a magical architecture solution.
But as a way to automate the repetitive and mechanically verifiable parts of modernization.
For example, a mining codemod can:
- detect service-to-service communication
- identify serialization patterns
- surface risky infrastructure usage
- measure migration scope
- generate org-wide visibility
Example:
Loading code sample...
This kind of tooling helps teams:
- prioritize migrations
- measure blast radius
- coordinate rollout sequencing
- track modernization progress across repositories
Instead of manually auditing thousands of files.
I wouldn’t rewrite service internals first.
I’d wrap what already exists.
Loading code sample...
The caller implicitly depends on:
- payload structure
- transport behavior
- serialization settings
- auth expectations
- retry semantics
Loading code sample...
And expose a stable boundary:
Loading code sample...
The key idea is not “perfect architecture.”
It’s explicit contracts.
One of the biggest hidden problems in legacy systems is inconsistent infrastructure behavior.
Serialization is a classic example.
Loading code sample...
Different defaults eventually create:
- compatibility bugs
- casing mismatches
- enum inconsistencies
- DateTime problems
- null handling drift
Loading code sample...
Then usage becomes:
Loading code sample...
This kind of standardization sounds boring.
But it dramatically improves predictability.
In large production systems, these changes should usually be rolled out incrementally because serialization differences can create subtle compatibility issues between services.
This is where coupling actually starts to drop.
Loading code sample...
Loading code sample...
And the infrastructure logic becomes centralized:
Loading code sample...
In real production systems, these clients usually also centralize:
- retries
- timeouts
- observability
- correlation IDs
- resiliency policies
- auth propagation
This is where platform consistency starts compounding.
Structural boundaries make security controls much easier to apply consistently across services.
Loading code sample...
Loading code sample...
Once boundaries become explicit, teams can enforce:
- auth policies
- encryption standards
- observability
- resiliency rules
- compliance requirements
More systematically.
You’ll often find business rules tightly coupled to controllers or transport handlers.
Loading code sample...
Loading code sample...
The goal is not “thin controllers.”
The goal is clearer separation between:
- transport concerns
- orchestration
- domain behavior
- infrastructure policies
Large-scale migrations are rarely “flip the switch” deployments. In production systems, teams usually roll changes out incrementally behind feature flags, canary deployments, compatibility layers, or staged rollouts to reduce operational risk while keeping feature delivery moving.
In these migrations, a large portion of the work is often repetitive and mechanically verifiable across many repositories and teams. Things like standardizing infrastructure usage, replacing deprecated APIs, or introducing safer boundaries can usually be automated reliably with deterministic compiler-aware tooling.
But not every change should be automated the same way.
Architectural decisions, rollout strategy, and domain-specific edge cases still require human judgment, local context, and nuanced decision-making. The goal is to use the right tool for the right task: deterministic tooling for repeatable changes, and AI systems or engineers for judgment-heavy ones.
Successful modernization is usually not about rewriting everything at once. It’s about making dependencies visible, introducing enforceable boundaries, automating repetitive transformations, and rolling changes out incrementally without breaking production. That’s what turns modernization from a risky one-time project into a repeatable engineering capability.